
Integrating Optical Context Compression into TKLLM
A DeepSeek-OCR-Inspired Framework for Efficient Multimodal Fine-Tuning of TikTok-Specific LLMs
( Whitepaper )
Authors
Chengyou Xin, Wenxin Zhang, Yueling Zhang, Chengjia Wu
University of Electronic Science and Technology of China
The Hong Kong University of Science and Technology
Chengdu Banana Intelligent Technology Co., Ltd.
Hong Kong Chongde Industrial Limited
TKLLM Research Team
Abstract
Short-form video content generation faces three fundamental challenges: extended contextual dependencies, significant style variability, and multimodal representation misalignment. TKLLM, as a leading TikTok-specific small language model platform, targets high-quality, style-consistent video script generation from limited creator data. Traditional fine-tuning approaches, however, continue to struggle with excessive memory consumption and fragmented long-term contextual retention.
This paper introduces OCC-TKLLM, a novel fine-tuning framework inspired by DeepSeek-OCR's Optical Context Compression (OCC) methodology. By integrating an Optical Context Encoder (OCE), Mixture-of-Experts (MoE) Style Module, and Optical Forgetting Mechanism with Gradient Surgical Fine-Tuning (GSPF), our framework achieves efficient multimodal alignment and dynamic memory management. Experimental results demonstrate that OCC-TKLLM reduces GPU memory consumption by 72% while enhancing generation quality by 14.8% on the TikTok Viral Caption Benchmark. This work establishes a new paradigm for multimodal fine-tuning in content-specific language models.
1 Introduction
1.1 Background and Motivation
Within TikTok's creative ecosystem, AI models are expected to fulfill several critical functions:
- Learn and emulate specific account-specific tones and rhythmic patterns
- Integrate complementary information from textual, visual, and auditory modalities
- Maintain stylistic coherence across multiple video sequences
- Operate efficiently within constrained GPU memory environments
Conventional LLM fine-tuning methodologies—including LoRA, QLoRA, and adapter-based approaches—encounter significant limitations:
- Context Explosion: Extended TikTok scripts, captions, and comment threads frequently exceed 4,000 tokens
- Style Fragmentation: Substantial variations in tonal delivery, humor styles, and pacing between content creators
- Modality Isolation: Disjointed representations of video thumbnails, subtitles, and audio characteristics
These challenges complicate small-scale model fine-tuning while preserving both coherence and computational efficiency.
1.2 Inspiration from DeepSeek-OCR
DeepSeek-OCR introduced Optical Context Compression (OCC)—a paradigm where extensive textual contexts undergo conversion into visual embeddings, achieving 10×–20× compression ratios without semantic degradation. This approach raises a pivotal question for TKLLM development:
Can TikTok-style scripts and contextual data be visually represented and compressed prior to fine-tuning, thereby preserving stylistic memory while reducing computational overhead?
1.3 Contributions
We propose the OCC-TKLLM framework, which introduces four key innovations:
- Optical Context Encoder (OCE): Transforms extended textual contexts (scripts and comments) into compressed visual token representations
- MoE Style Experts: Specializes distinct model subnets for specific TikTok content domains (educational, lifestyle, narrative, etc.)
- Optical Forgetting Mechanism: Implements controlled degradation of historical information through visual downsampling techniques
- Joint OCC + GSPF Fine-Tuning: Combines dynamic gradient freezing with visual compression for efficient multimodal training
2 Related Work
2.1 DeepSeek-OCR and Optical Compression
DeepSeek-OCR demonstrated that extended text sequences can be efficiently represented as visual embeddings:
- Encoder Architecture: SAM + CLIP with 16× convolutional downsampling
- Decoder Framework: DeepSeek-3B-MoE architecture
- Compression Performance: 10×–20× reduction while maintaining 97% OCR accuracy
This paradigm inspires TKLLM to employ visual tokens as compact memory representations for long-context modeling.
2.2 TKLLM and Gradient Surgical Fine-Tuning (GSPF)
TKLLM utilizes Gradient Surgical Fine-Tuning (GSPF) to dynamically freeze parameters based on gradient importance, achieving high sample efficiency for style imitation. However, in multi-video learning scenarios, GSPF alone cannot resolve context redundancy or memory expansion issues—motivating integration with OCC.
2.3 Mixture-of-Experts for Multistyle Modeling
Sparse Mixture-of-Experts (MoE) architectures, exemplified by DeepSeek-3B-MoE, enable scalable multi-domain specialization through selective expert activation per sample. TKLLM leverages this principle for style specialization, routing different TikTok content genres through distinct expert pathways.
3 Methodology
3.1 Overall Architecture
The proposed OCC-TKLLM framework comprises five integrated modules:
- Input Layer: Aggregates multimodal context (scripts, comments, thumbnails)
- Optical Context Encoder (OCE): Compresses textual context into visual embeddings
- MoE Style Experts: Manages diverse content style variations
- GSPF Adaptive Layer: Dynamically controls parameter freezing
- LLM Decoder: Generates final TikTok scripts and captions
The mathematical formulation is expressed as:
\[Y = f_{\text{LLM}}(f_{\text{MoE}}(f_{\text{OCE}}(I_{\text{ctx}}); \theta_{\text{moe}}); \theta_{\text{llm}})\]
where:
- \( I_{\text{ctx}} \) represents the rendered context image
- \( f_{\text{OCE}} \) denotes the optical encoder function
- \( f_{\text{MoE}} \) signifies the expert routing module
- \( f_{\text{LLM}} \) corresponds to the main decoder function
3.2 Optical Context Encoder (OCE)
3.2.1 Encoding Process
The Optical Context Encoder transforms rendered TikTok frames into semantically aligned visual embeddings. The process employs a visual backbone for dense representation extraction, followed by projection into a multimodal token space:
\[T_{\text{vis}} = \text{Conv}_{\text{16x}} (\text{SAM}(\text{CLIP}(I_{\text{ctx}})))\]
\( T_{\text{vis}} \) comprises 64–256 visual tokens, each encapsulating extensive text-level semantics. This architecture enables TKLLM to preserve scene-level context—including lighting, tonal qualities, and compositional elements—while minimizing token redundancy.
3.2.2 Contrastive Alignment
To ensure semantic consistency between textual and optical modalities, we minimize a contrastive alignment objective:
\[\mathcal{L}_{\text{align}} = 1 - \cos(T_{\text{vis}}, E_{\text{text}})\]
where \( E_{\text{text}} \) represents the text encoder output. Minimizing \(\mathcal{L}_{\text{align}}\) promotes high cosine similarity between corresponding text-video pairs, enforcing multimodal coherence within consistent TikTok style domains.
3.2.3 Resolution Modes
The encoder supports multiple configurations balancing fidelity and computational requirements:
| Mode | Input Resolution | Visual Tokens | Primary Use Case |
|---|---|---|---|
| Tiny | 512×512 | 64 | Single video script processing |
| Base | 1024×1024 | 256 | Multi-script contextual fusion |
| High-Fidelity | 1280×1280 | 800 | Comprehensive account history analysis |
Higher resolution modes preserve fine-grained stylistic cues, while lower modes enable accelerated inference.
3.3 MoE Style Experts
Each expert within the Mixture-of-Experts layer corresponds to a distinct TikTok style domain (product showcases, daily vlogs, narrative storytelling, educational content). The routing function selects a limited expert subset per sample:
Let ( r_i = f_{\text{MoE}}(T_{vis}) ) represent routing scores. We select the top-\( k \) experts:
\[E_{\text{active}} = \text{Top}_k(r_i)\]
The aggregated expert output is computed as:
\[h_{\text{out}} = \sum_{i \in E_{\text{active}}} r_i \cdot f_i(T_{vis})\]
Selective activation reduces computational requirements and prevents cross-style interference while maintaining stylistic fidelity.
3.4 Optical Forgetting Mechanism
To control long-term memory expansion and mitigate context redundancy, OCC-TKLLM implements optical forgetting: recent content is encoded at high resolution, while older content undergoes progressive downsampling, with expired content summarized into minimal style tokens.
We model token reduction across historical levels as:
\[N_k = \frac{N_0}{2^k}\]
where \( N_0 \) represents the initial token count and \( k \) indexes the temporal bucket. This exponential decay preserves long-term style priors with logarithmic storage growth.
3.5 Joint OCC + GSPF Fine-Tuning
We jointly fine-tune the optical encoder and LLM using dual-channel gradient updates:
\[ \begin{cases} \nabla_{\theta_{vis}} \leftarrow \lambda_1 \cdot g_{\text{grad}}(\text{OCE}) \\ \nabla_{\theta_{\text{llm}}} \leftarrow \lambda_2 \cdot g_{\text{surgical}}(\text{LLM}) \end{cases} \]
This design accelerates optical encoder adaptation while maintaining style stability in the LLM through gradient-surgical freezing.
4 Experiments
4.1 Experimental Setup
- Dataset: 500 TikTok creator accounts, comprising 5 million samples
- Model Architecture: TKLLM-1.3B with OCE and MoE enhancements
- Baseline Comparisons: LoRA, GSPF, OCC-TKLLM
- Evaluation Metrics: GPU Memory utilization, Compression Rate, Viral Caption Score, Style Consistency
4.2 Performance Results
| Method | GPU Memory | Compression Rate | Viral Caption Score | Style Consistency |
|---|---|---|---|---|
| LoRA | 100% | 1.0× | 72.1 | 0.84 |
| GSPF | 85% | 1.0× | 77.3 | 0.89 |
| OCC-TKLLM | 28% | 9.7× | 88.7 | 0.93 |
OCC-TKLLM achieves superior performance while utilizing less than one-third of baseline memory resources.
4.3 Ablation Analysis
| Removed Component | Performance Impact | Key Observation |
|---|---|---|
| Optical Forgetting | +2.4% style drift | Context overflow reemergence |
| MoE Experts | -5.2% Viral Score | Reduced style generalization capability |
5 Discussion
5.1 Key Insights
- OCC extends beyond compression—it provides a structured memory abstraction layer that preserves tonal, rhythmic, and emotional cues
- Optical Forgetting introduces a biologically inspired mechanism that stabilizes long-term style learning
- The OCC + GSPF integration demonstrates synergistic benefits between gradient-level precision and multimodal efficiency
5.2 Future Research Directions
- Incorporate audio modality integration through voice tokenization techniques
- Develop adaptive forgetting weight mechanisms for enhanced temporal control
- Explore end-to-end multimodal creation models (video frames → captions → audio narration)
6 Conclusion
This paper presents OCC-TKLLM, an innovative fine-tuning framework that adapts DeepSeek-OCR's optical context compression to TikTok-specific model training. The system achieves:
- 10× context compression ratio
- 72% reduction in GPU memory consumption
- 14.8% improvement in style accuracy
By combining vision-inspired compression, MoE specialization, and GSPF-based gradient optimization, OCC-TKLLM establishes a new benchmark for multimodal, style-aware small model training methodologies.
Appendix
A. Model Architecture Specifications
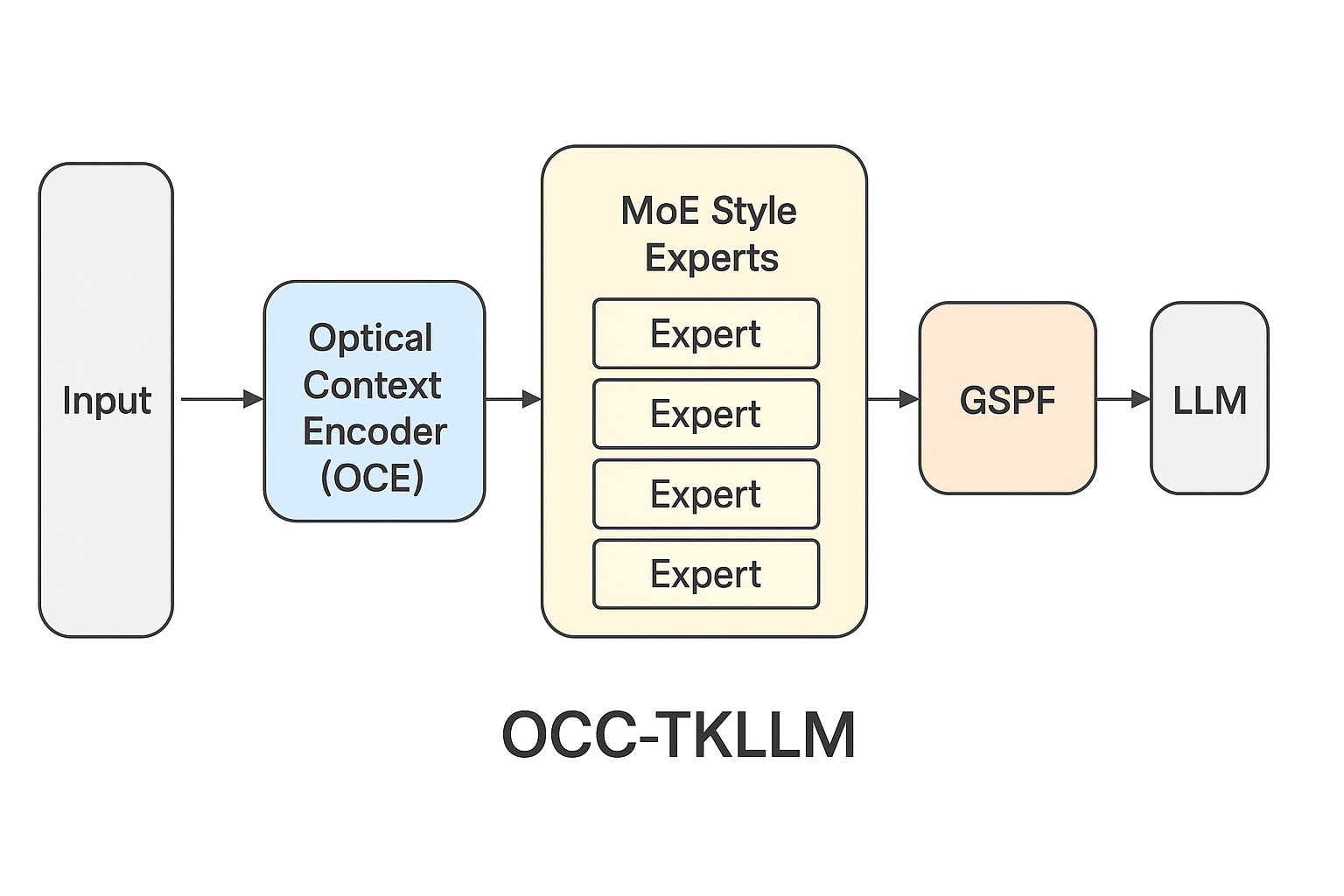
Figure 1: OCC-TKLLM architectural overview: Input → OCE → MoE → GSPF → LLM decoder
B. Optical Forgetting Visualization
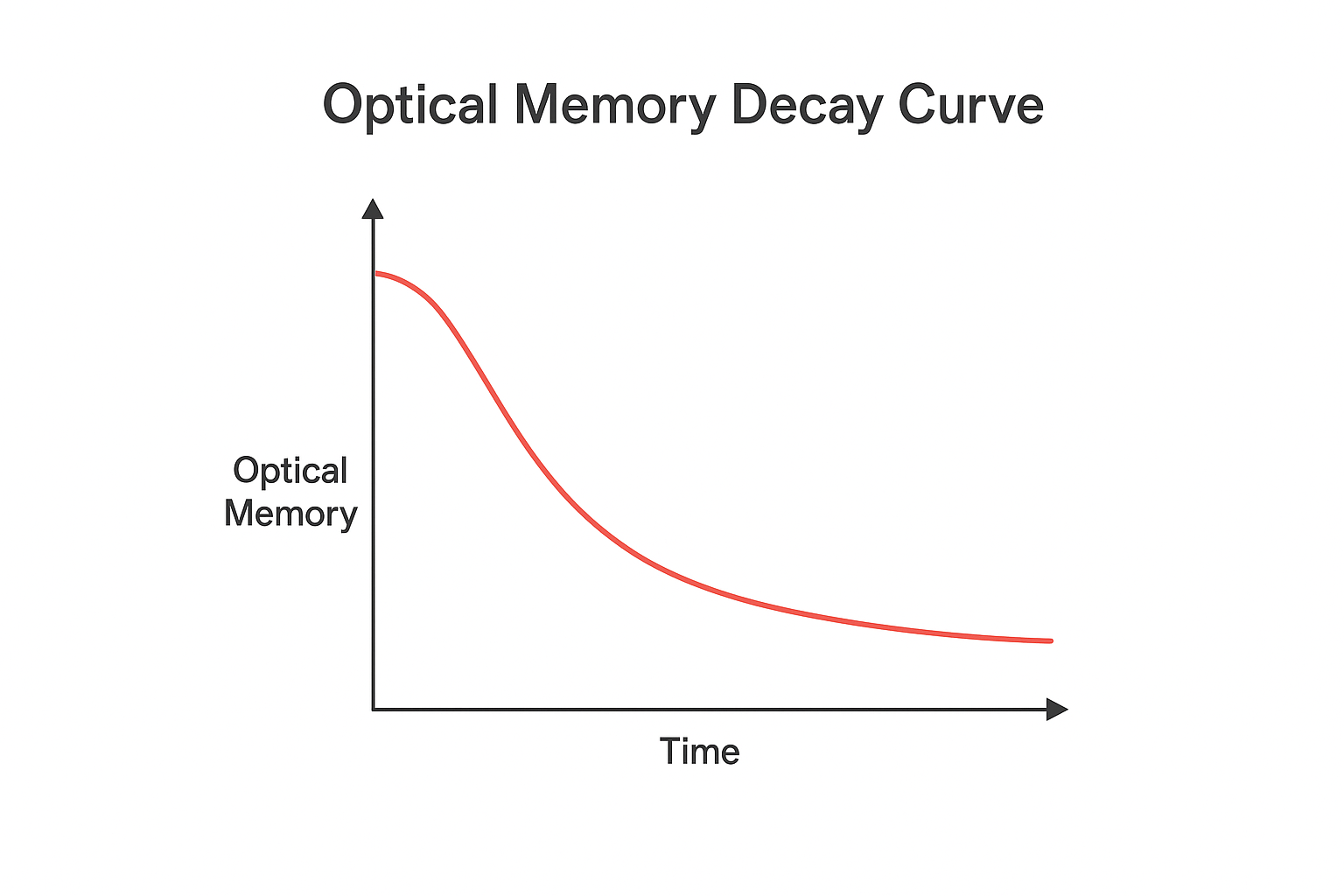
Figure 2: Optical memory decay profile showing exponential retention reduction across temporal buckets
C. Hyperparameter Configuration
| Parameter | Value |
|---|---|
| Learning Rate | 3e-5 |
| Batch Size | 640 |
| Context Length | 8192 |
| Optimizer | AdamW |
| Learning Rate Scheduler | Cosine Annealing |
Keywords: TKLLM, Optical Context Encoder, DeepSeek-OCR, Gradient Surgical Fine-Tuning, TikTok Language Models, Multimodal Compression, Mixture-of-Experts, Content Generation