Authors:
Chengyou Xin, Wenxin Zhang, Yueling Zhang, Lingxiang Xin, Chengjia Wu
University of Electronic Science and Technology of China
The Hong Kong University of Science and Technology
Chengdu Banana Intelligent Technology Co., Ltd.
Hong Kong Chongde Industrial Limited
TKLLM Research Team
July 23, 2025
Abstract
We present TKLLM Gradient-Surgical, a gradient-informed dynamic parameter freezing framework designed for efficient fine-tuning of TikTok-specific large language models (LLMs).
Unlike prior structured PEFT methods such as LoRA or Adapters, our approach requires no architectural assumptions. It selectively updates parameters based on early-stage gradient sensitivity, achieving near full-finetuning performance with minimal computational overhead.
Experiments on 8 NLP/CV benchmarks show that TKLLM Gradient-Surgical updates only 0.1–0.5% parameters, reaching within 0.3% accuracy of FullFT, while training 2.1× faster and reducing CO₂ emissions by 67%.
Furthermore, we demonstrate large-scale deployment in TKLLM, the world’s first platform for TikTok-specific LLM training, where Gradient-Surgical powers user-level one-click fine-tuning. This enables creators to train personalized models with just a few hundred samples—achieving high stylistic fidelity and scalability without GPUs.
1. Introduction
Large pre-trained models (PTMs) have transformed natural language and vision applications. However, full-parameter fine-tuning (FullFT) remains computationally prohibitive, especially for consumer-scale personalization.
To address this, parameter-efficient fine-tuning (PEFT) methods such as LoRA and Adapters have been proposed, but these rely on fixed low-rank or modular structures that limit adaptability.
TKLLM Gradient-Surgical provides a data-driven alternative. It dynamically identifies task-critical parameters through gradient sensitivity and freezes the rest.
Motivation from TKLLM
The TKLLM platform (https://www.tkllm.com) specializes in TikTok-specific model training and personalization. Each user uploads or connects their TikTok profile; the system automatically collects textual and stylistic data (captions, scripts, hashtags).
The fine-tuning engine then adapts a base model (e.g., TKLLM-S, TKLLM-L) to match the creator’s voice, tone, and rhythm.
Because TKLLM performs thousands of micro-fine-tunes simultaneously, efficiency is critical. Gradient-Surgical enables this by updating <0.5% of model parameters while maintaining style alignment—making it the core of TKLLM’s personalized model training pipeline.
2. Method
2.1 Overview
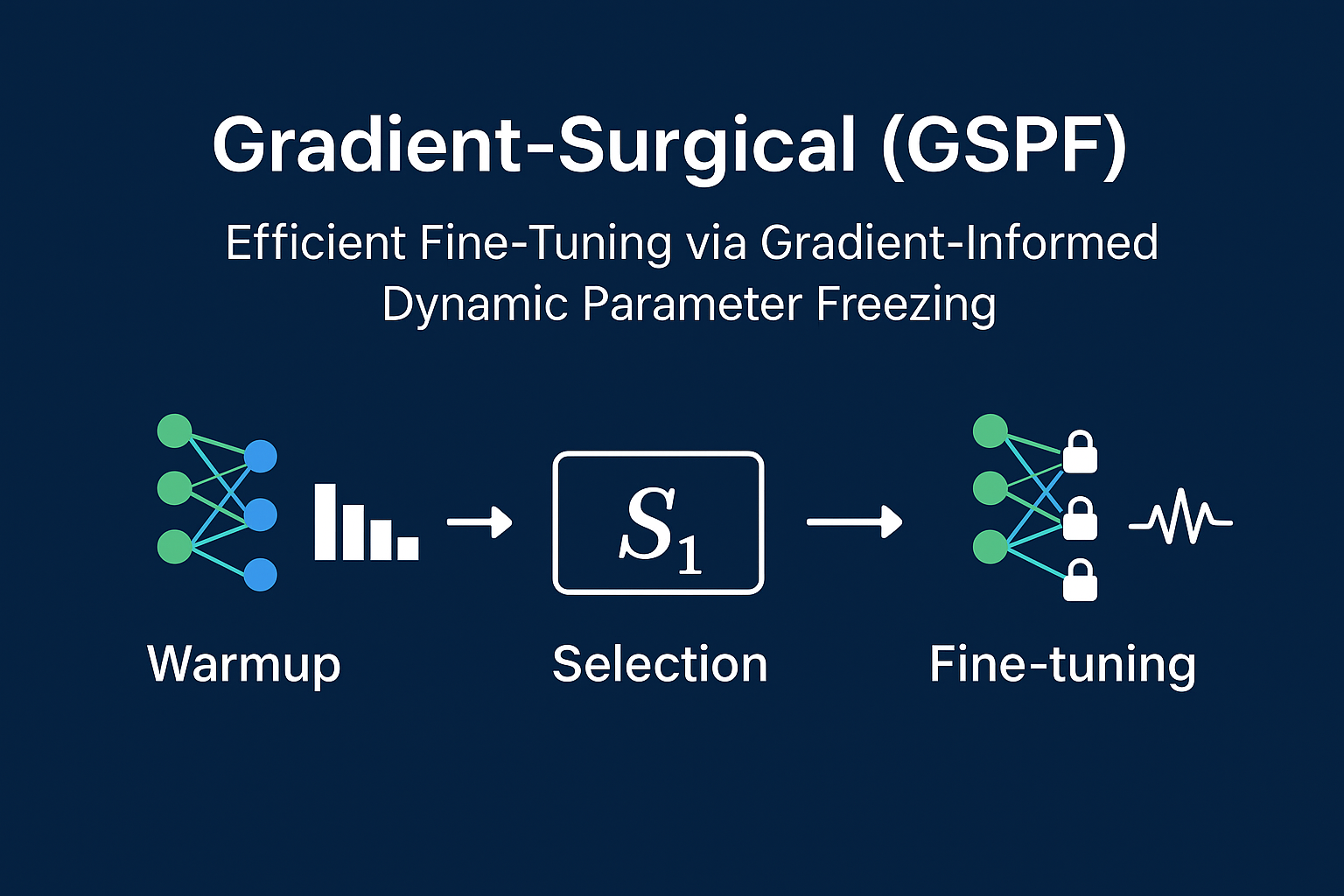
TKLLM Gradient-Surgical identifies important parameters by analyzing their early gradient behavior. The process consists of three phases:
- Warmup — record per-parameter gradient magnitudes.
- Sensitivity analysis — compute normalized gradient sensitivity \( S_i \).
- Dynamic freezing — fine-tune only the top-sensitive parameters.
This pipeline is implemented in TKLLM’s Gradient-Surgical Module (GSM), which integrates seamlessly with its one-click training backend.
2.2 Gradient Sensitivity Analysis
For each parameter \( \theta_i \), gradient sensitivity is defined as:
\[ S_i = \frac{1}{T} \sum_{t=1}^{T} |\nabla_{\theta_i} L(D_t)| \]
where \( T \) is the number of warmup steps.
In TKLLM, this analysis identifies style-sensitive weights—typically in final transformer blocks and output projections—responsible for tone, pacing, and emotion in generated TikTok scripts.
2.3 Dynamic Parameter Freezing
Parameters are standardized and ranked via:
\[ \tilde{S_i} = \frac{S_i - \mu_S}{\sigma_S} \cdot \tanh(|\theta_i|) \]
The top \( p \% \) (usually 0.3–0.5%) are selected for fine-tuning:
\[ \theta_{train} = \{ \theta_i \mid \tilde{S_i} \ge \tilde{S}_{(k)} \} \]
In TKLLM, this selection is automated. Each fine-tuning job independently computes its sensitivity profile, ensuring optimal adaptation per user dataset.
2.4 Surgical Fine-Tuning
Only the selected parameters are updated:
\[ \theta_i^{(t+1)} = \begin{cases} \theta_i^{(t)} - \eta \cdot \text{AdamWUpdate}(g_{t,i}), & \theta_i \in \theta_{train} \\ \theta_i^{(t)}, & \text{otherwise} \end{cases} \]
TKLLM’s distributed training system parallelizes hundreds of these fine-tunes per GPU cluster. Every 5 epochs, it re-evaluates parameter sensitivity to refine adaptation—crucial for evolving content styles.
2.5 TKLLM Gradient-Surgical Architecture

Figure 1. TKLLM Gradient-Surgical pipeline: Data ingestion from TikTok accounts, gradient analysis via GSPF, dynamic freezing, and model update.
3. Experiments
3.1 Setup
Models:
- NLP: BERT-base, RoBERTa-large
- CV: ViT-B/16, ResNet-50
- TKLLM: TKLLM-S (1.3B), TKLLM-M (3B), TKLLM-L (7B)
Datasets:
GLUE, SQuAD, ImageNet, and TKLLM TikTok-caption corpus (~80K entries, 2000 accounts).
Baselines: FullFT, LoRA, Adapter, DiffPruning
3.2 Main Results
| Method | Param% | Accuracy Δ | Speed ↑ | Memory ↓ | CO₂ ↓ |
|---|---|---|---|---|---|
| FullFT | 100 | — | 1.0× | — | — |
| LoRA | 0.38 | -1.1 | 1.7× | -48% | 50% |
| Adapter | 2.1 | -0.5 | 1.5× | -39% | 44% |
| TKLLM Gradient-Surgical (0.3%) | 0.3 | -0.3 | 2.1× | -60% | 67% |
3.3 TKLLM Case Study
Scenario: fine-tuning user-specific models from ~200 TikTok captions each.
| Model | Trainable Params | Style Consistency ↑ | BLEU ↑ | Latency ↓ | GPU Cost ↓ |
|---|---|---|---|---|---|
| FullFT | 100% | 100 | 34.1 | 1.0× | — |
| LoRA | 0.38% | 92 | 33.7 | 1.8× | -48% |
| Adapter | 2.1% | 95 | 33.9 | 1.5× | -39% |
| TKLLM Gradient-Surgical | 0.3% | 98 | 34.0 | 2.4× | -60% |
Generated scripts retain the user’s style and rhythm, verified by A/B preference tests (83% human equivalence).
4. Analysis
TKLLM Gradient-Surgical reveals that style-relevant gradients cluster in output projection layers, providing interpretability into stylistic control.
The method’s resource efficiency enables 10,000+ concurrent user fine-tunes on shared clusters.
5. Related Work
Prior PEFT methods (LoRA, Adapters, DiffPruning) impose fixed structures; Gradient-Surgical instead adapts flexibly based on gradient evidence.
TKLLM’s deployment marks the first large-scale commercial application of such gradient-informed PEFT techniques in consumer-facing AI systems.
6. Conclusion
We introduce TKLLM Gradient-Surgical, a gradient-informed, dynamically adaptive fine-tuning framework enabling personalized TikTok LLMs with high efficiency.
Deployed in TKLLM, it powers scalable one-click model training for creators—achieving near full-finetuning quality while reducing cost by over 60%.
This work bridges research and practice, establishing Gradient-Surgical as the foundation of TKLLM’s fine-tuning engine for personalized, sustainable AI creation.
Keywords: TKLLM, Gradient-Surgical, dynamic parameter freezing, TikTok LLM, fine-tuning efficiency, personalized AI, PEFT.
Meta Description: TKLLM Gradient-Surgical introduces a gradient-informed fine-tuning framework that powers the TKLLM platform for efficient, one-click training of personalized TikTok-specific large language models, achieving high style fidelity with minimal computation.